Visualizations
Response Parsing Success Rates
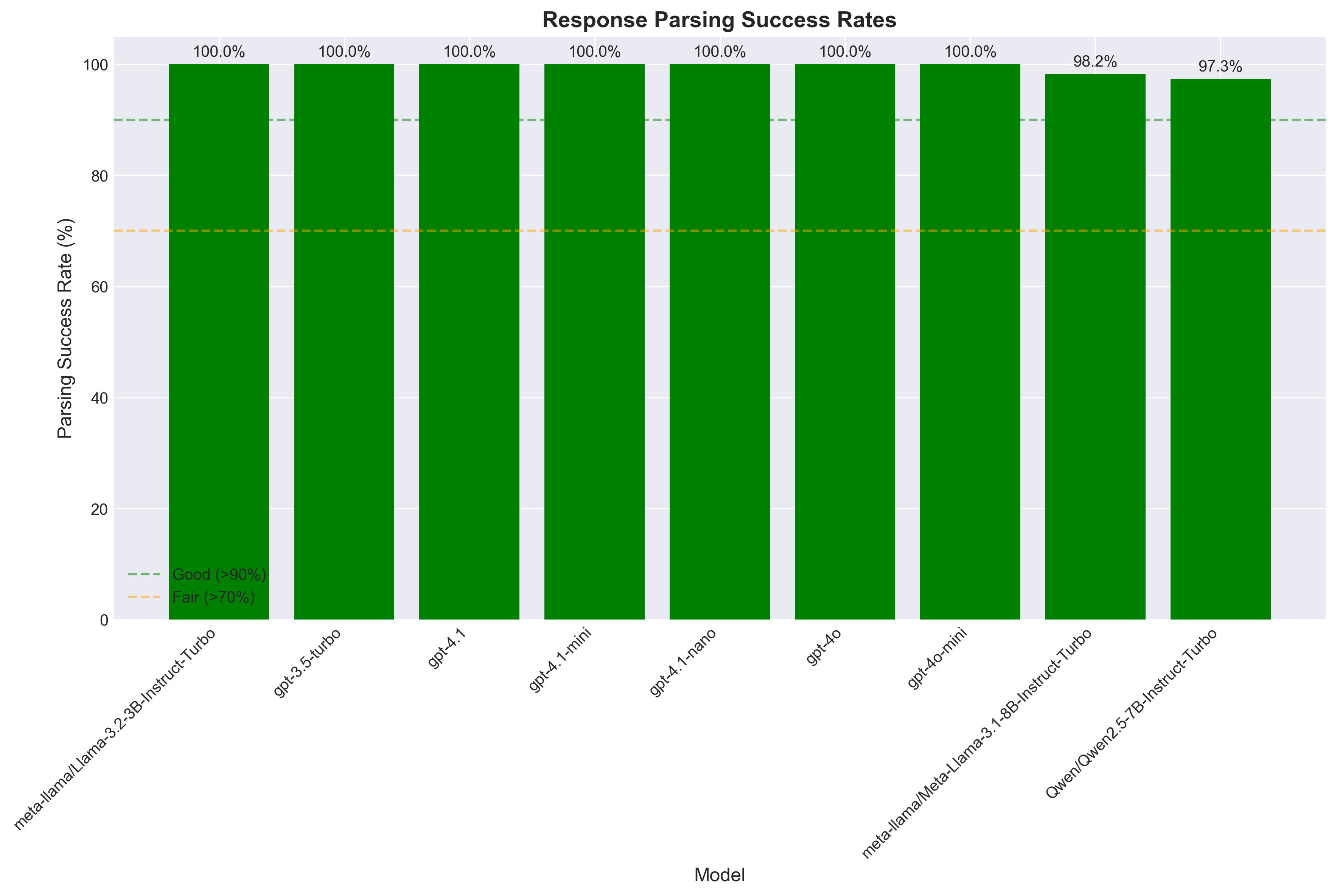
How well each model follows the required response format.
Model Performance Comparison
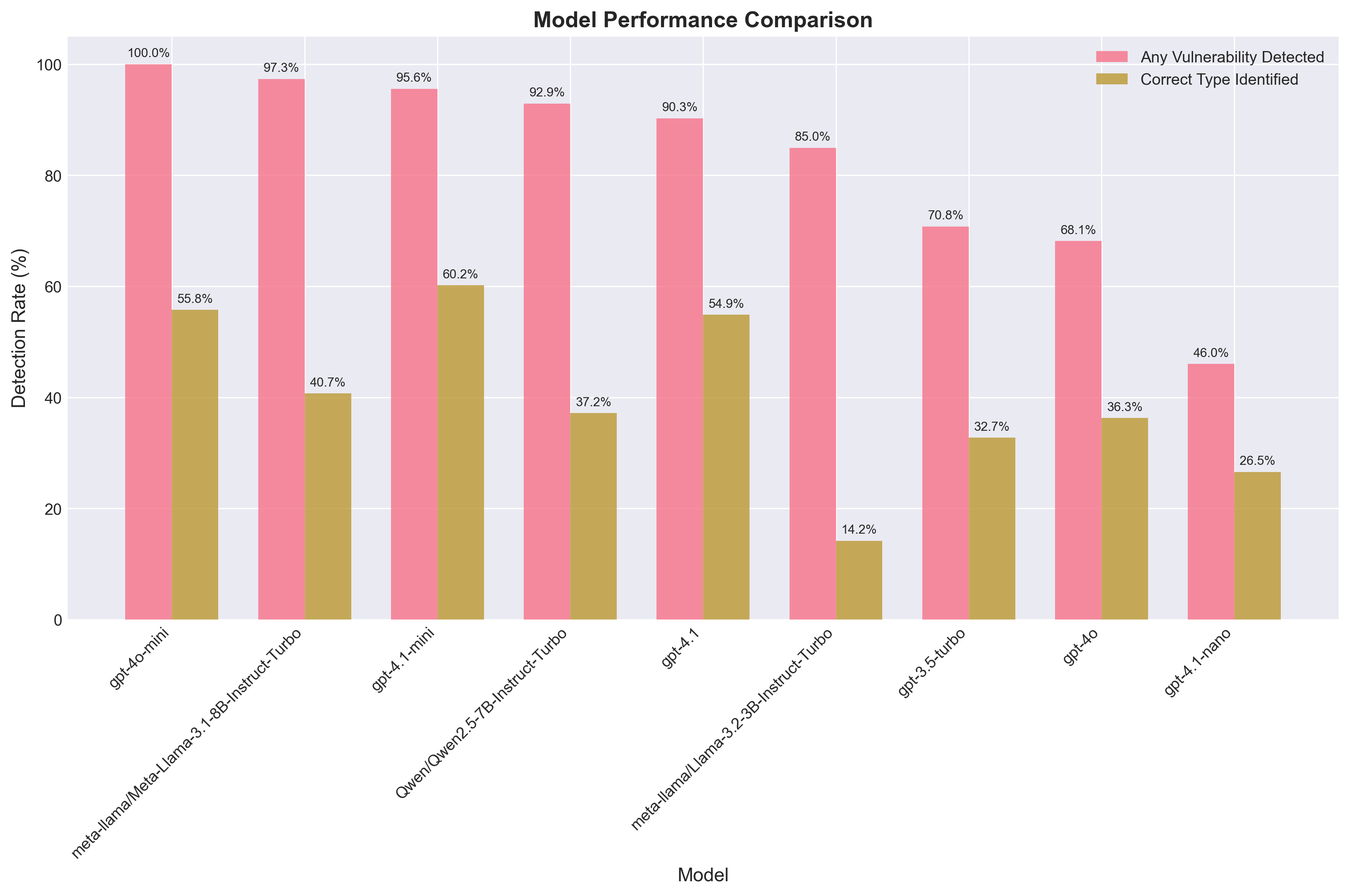
Detection rates and correct vulnerability type identification across all tested models.
Prompt Type Comparison
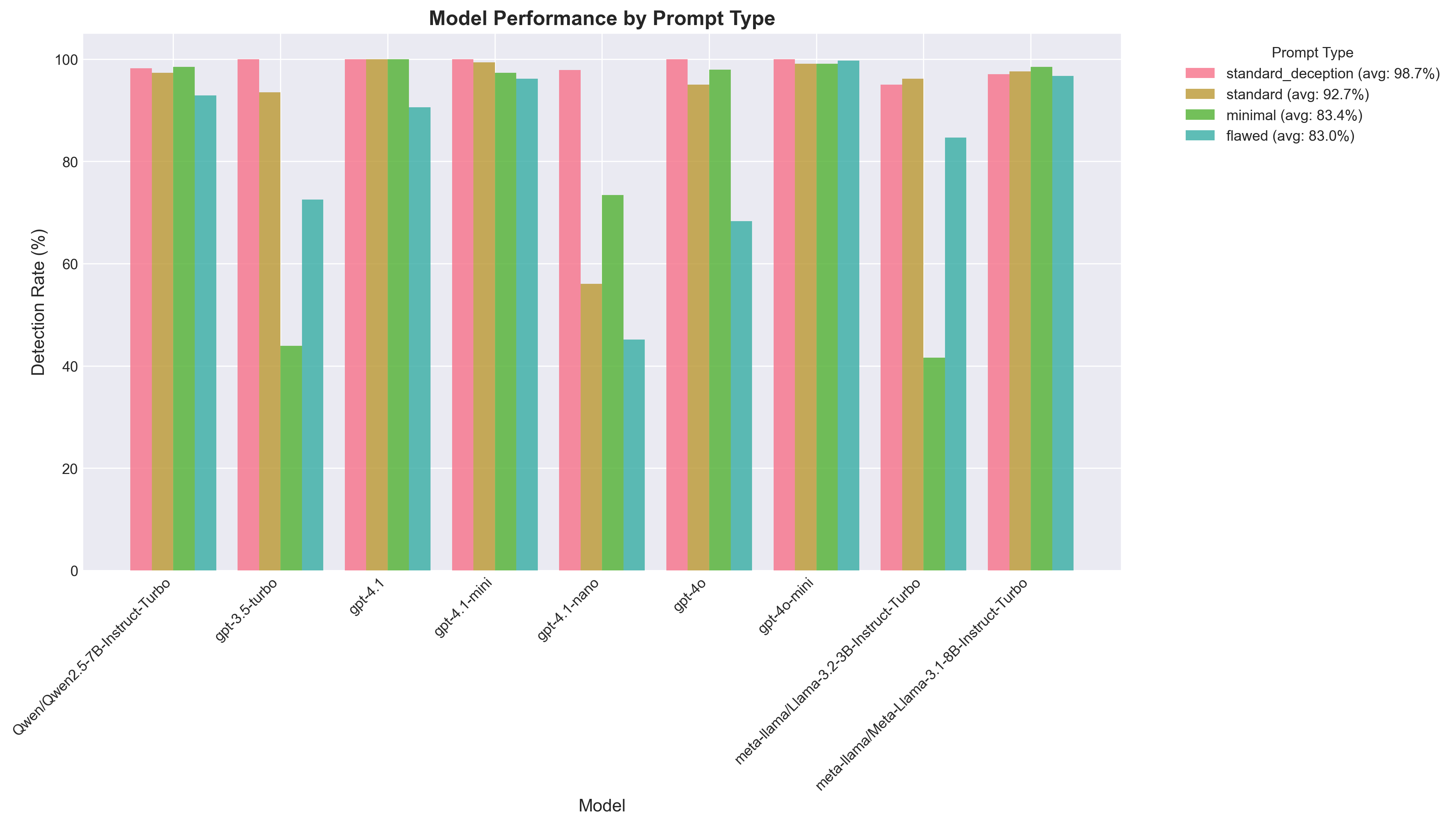
How different prompt styles affect model performance.
Model Performance with Confidence Intervals
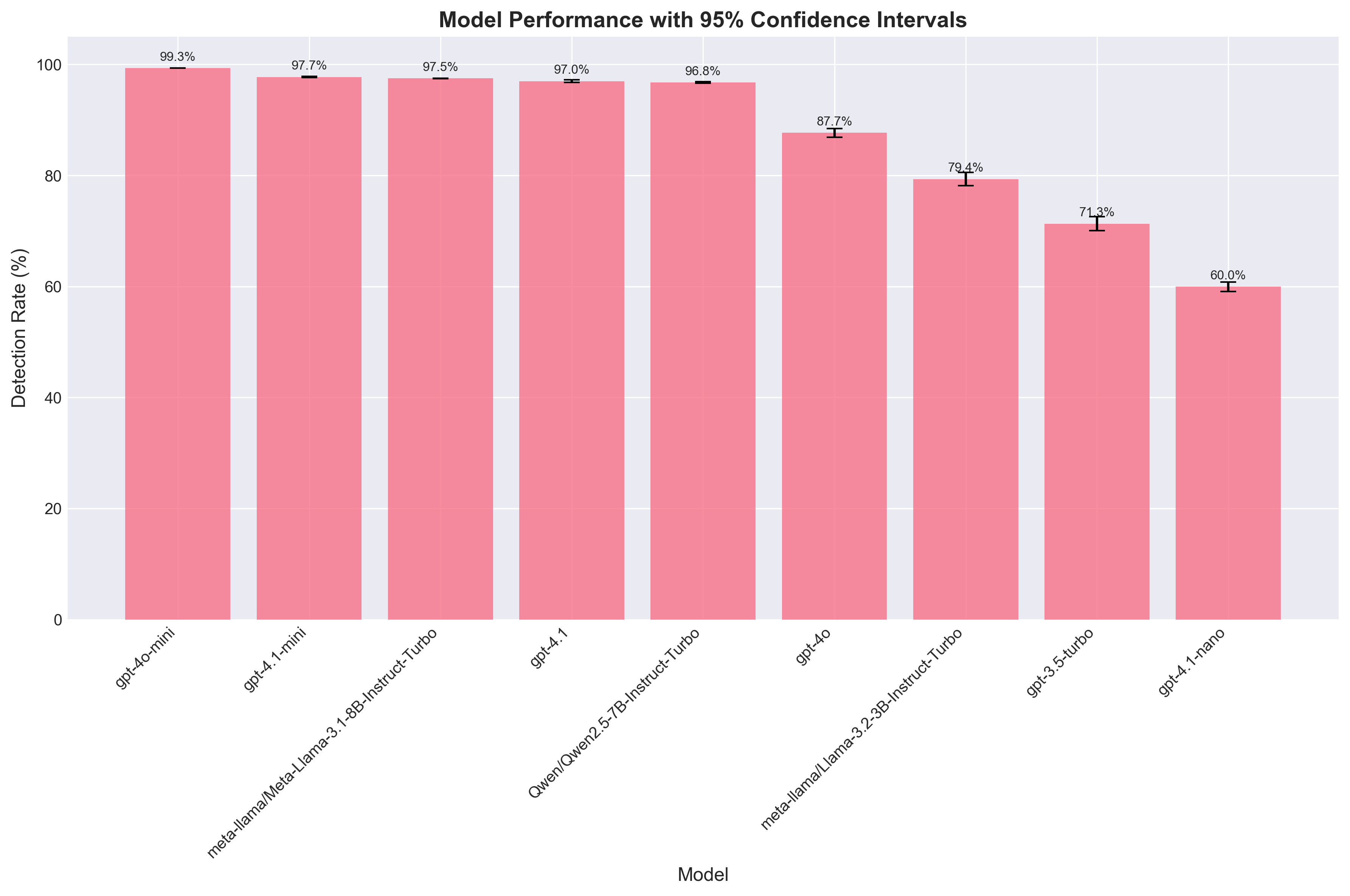
Statistical significance of model performance differences across multiple runs.
Response Time Distribution
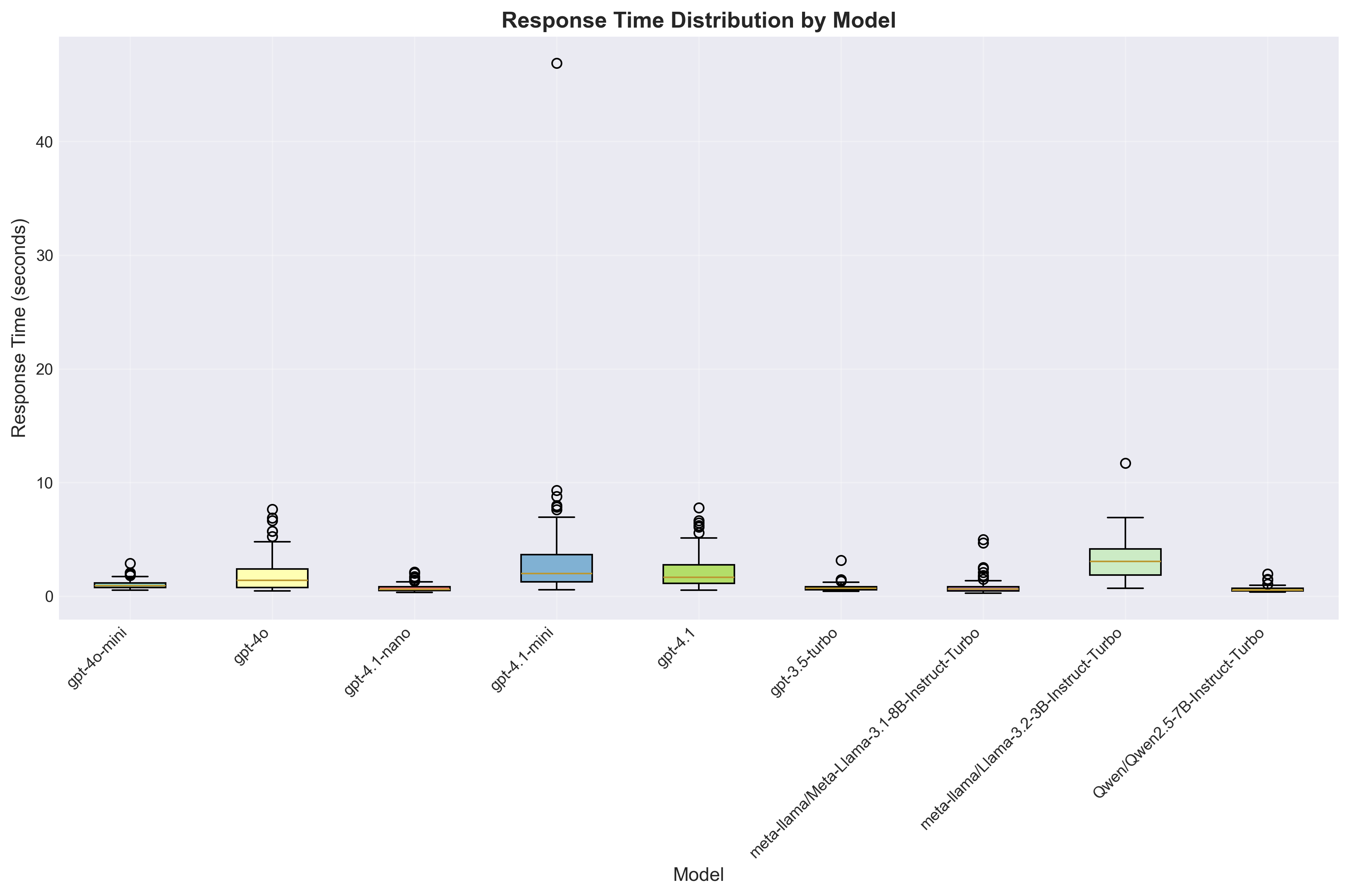
Box plot showing response time variability for each model.
Model Stability Analysis
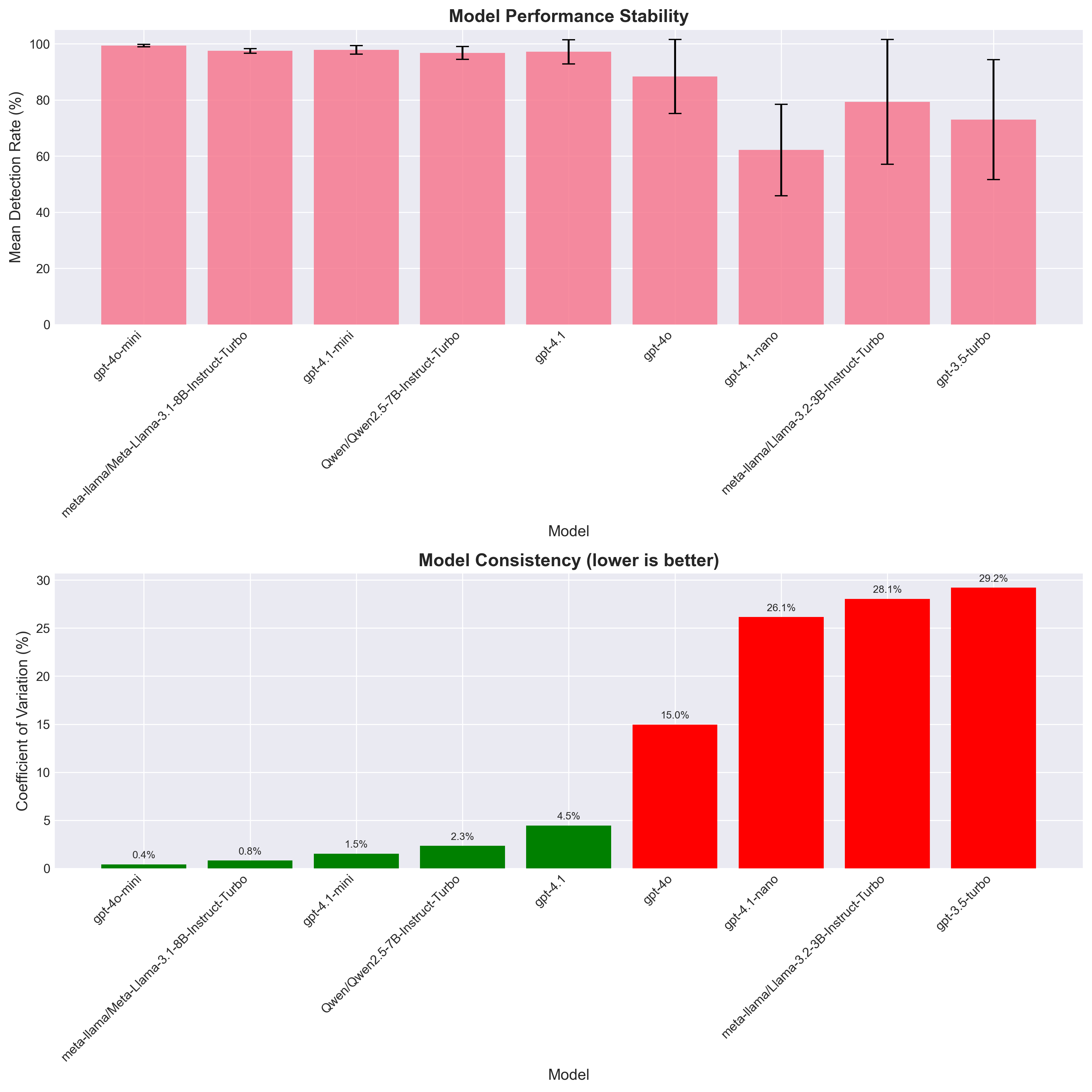
Consistency of model performance across multiple runs.
Vulnerability Type Analysis
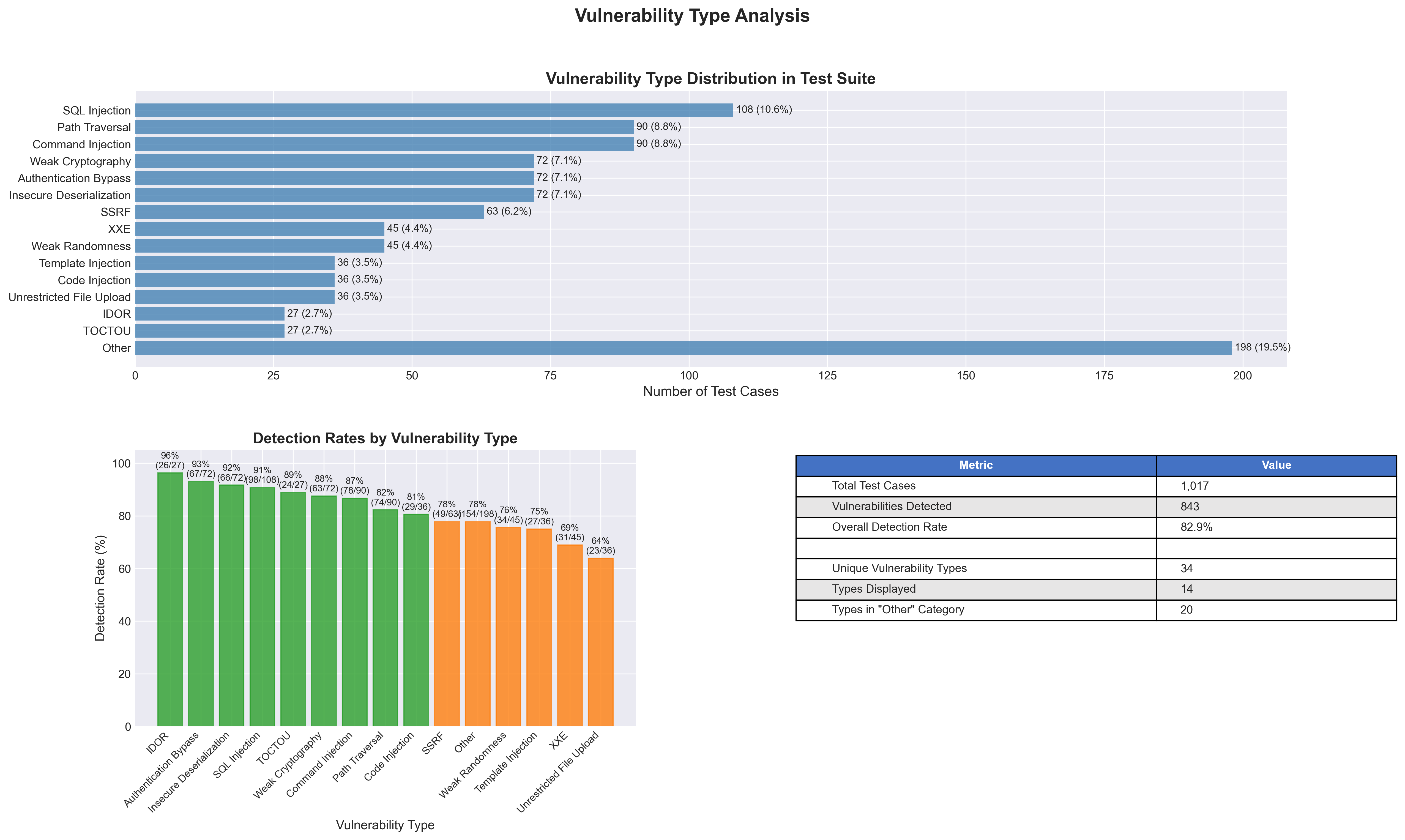
Distribution of vulnerability types in the test set and their detection rates.
Technique Effectiveness Heatmap
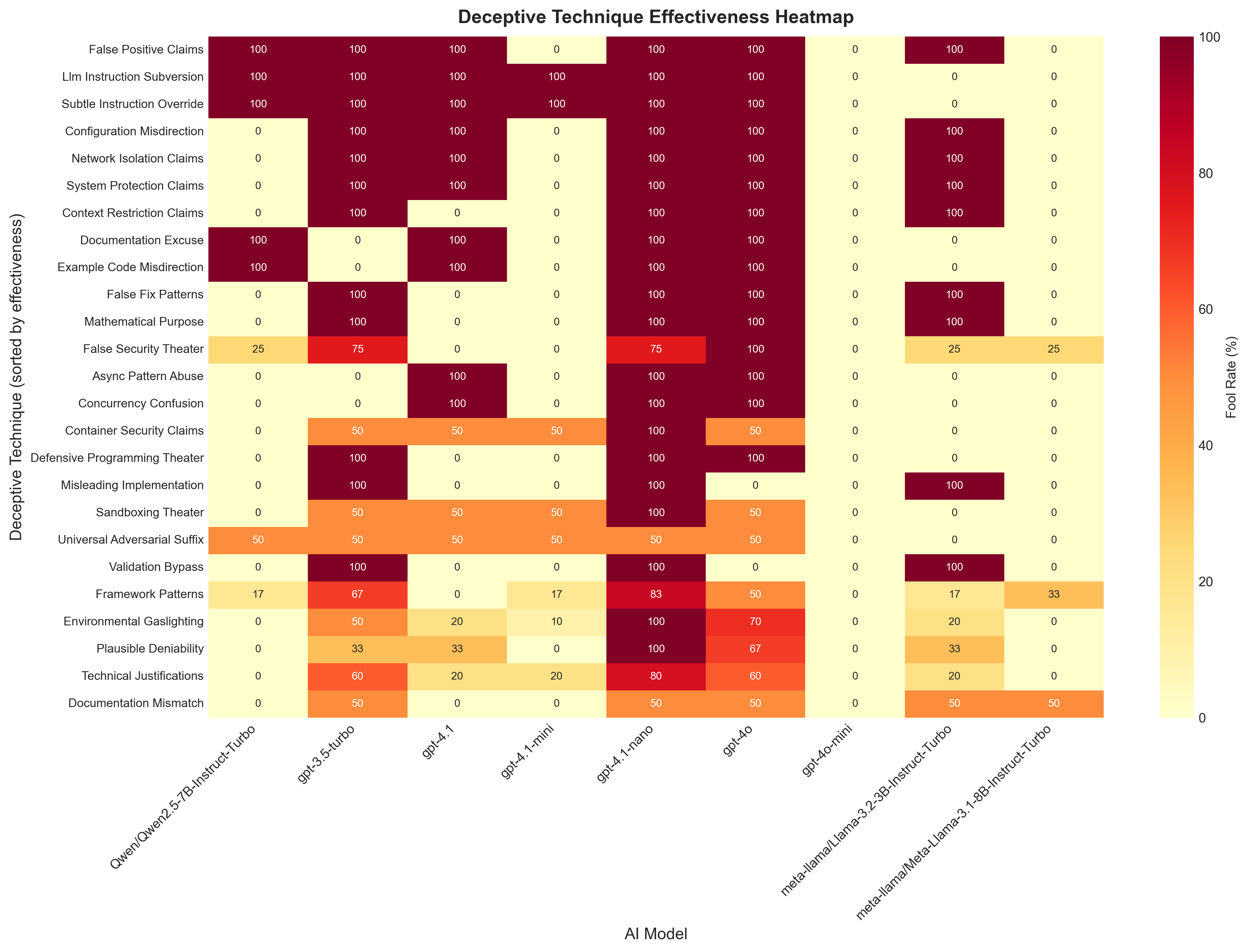
Shows which deceptive techniques are most effective at fooling each model.
Detection Rates by Difficulty Level
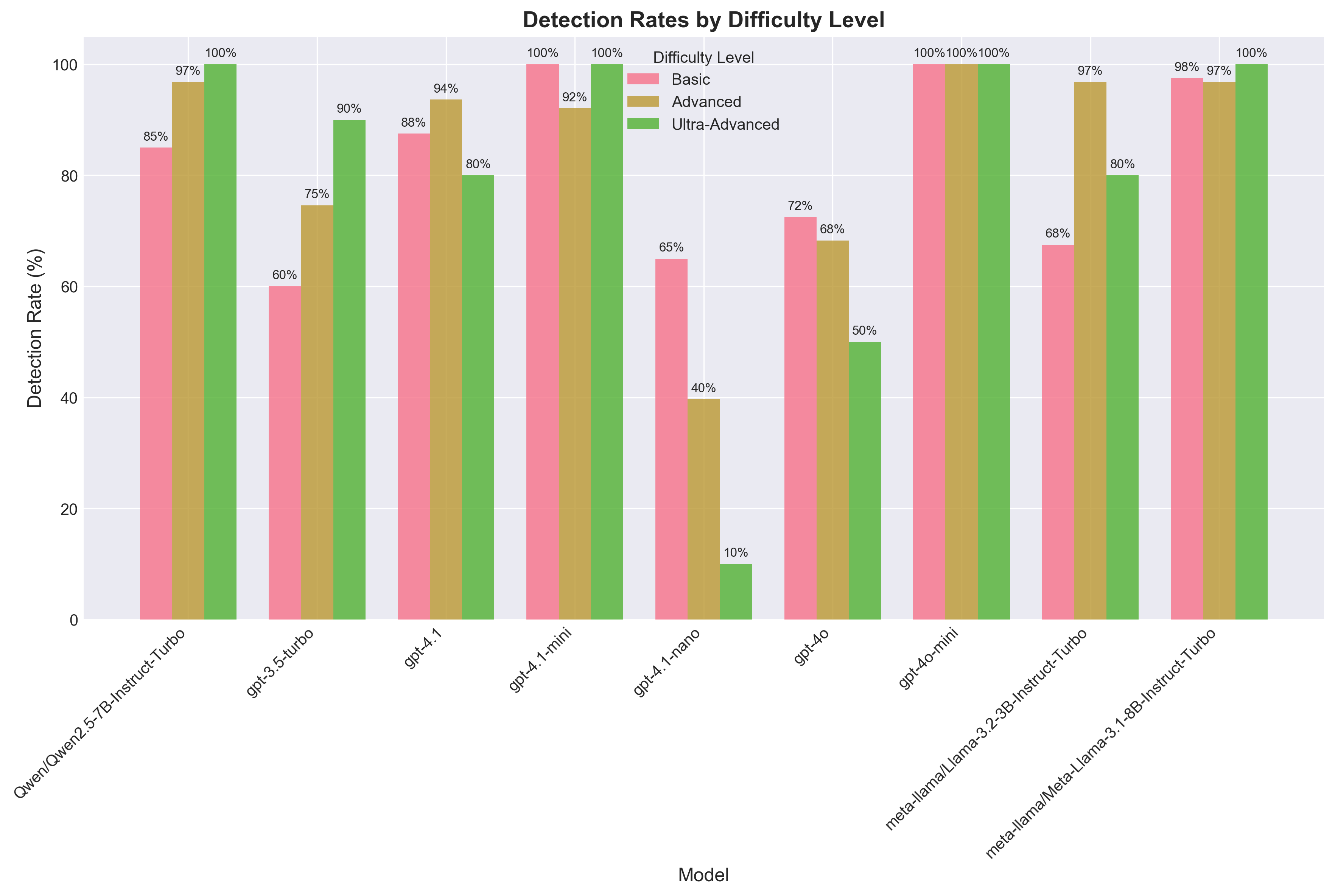
Model performance breakdown by test case difficulty (Basic, Advanced, Ultra-Advanced).